Redis
Redis
1. Redis 概述
1.1 简介
Redis(REmote DIctionary Server) 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。
特性
性能高
丰富的数据类型
支持事务
内建replication及集群
支持持久化
单线程,原子性操作(后续引入多线程,可配置开关)
1.2 NoSQL数据库
NoSQL(Not Only SQL源于Mongo) 是非关系型数据库的统称,主要用于解决Web2.0时代带来的大规模数据处理挑战。
Web2.0时代背景
- UGC (User Generate Content):用户由被动接收转为主动产生内容
- SNS (Social Network Society):社交网络的兴起,如Facebook、Twitter、WeChat等
1.2.1 四大分类
键值(Key-Value)存储
- 特点:使用哈希表,具有特定键和指针
- 优势:简单、易部署
- 代表产品:Redis, Tokyo Cabinet/Tyrant, Voldemort, Oracle BDB
列存储数据库
- 应用:分布式海量数据存储
- 特点:面向列的存储和检索
- 代表产品:Cassandra, HBase, Riak
文档型数据库
- 特点:类似键值存储,但支持嵌套键值对
- 数据格式:JSON等半结构化文档
- 代表产品:MongoDB, CouchDB, SequoiaDB
图形(Graph)数据库
- 特点:使用灵活的图形模型
- 应用:社交网络关系存储
- 代表产品:Neo4J, InfoGrid, Infinite Graph
1.2.2 适用场景
- 数据模型简单
- 需要更灵活的系统架构
- 高性能要求
- 数据一致性要求不高
- 易于映射复杂值的环境
1.3 源码编译与调试
源码下载: git地址 或者 Index of /releases/
wget也可以下载:
wget http://download.redis.io/releases/redis-${version}.tar.gz
tar xzf redis-6.0.8.tar.gz执行编译:
- 修改配置文件中的daemon为yes
- 禁用gcc编译优化,将makefile文件中OPTIMIZATION?=-O2修为-O0,可直接使用源码包下的二进制程序
- gdb redis-server [conf],配合gdb相关命令
- 也可以直接开启server.c的main测试函数
1.4 压测
Redis-benchmark 是官方自带的 Redis 性能测试工具,可以有效的测试 Redis 服务的性能。
redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests]> [-k <boolean>]1.5 安装配置
# Ubuntu安装
sudo apt-get update
sudo apt-get install redis-server
# 启动服务
redis-server
# 客户端连接
redis-cli
# 测试连接
redis 127.0.0.1:6379> ping
PONGPython环境配置
# 方式1:pip安装
sudo pip install redis
# 方式2:easy_install
sudo easy_install redis
# 方式3:源码安装
# 详见:https://github.com/WoLpH/redis-py2. 基本数据结构
Redis 共有 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)对应的底层数据结构实现如下表:
| String | List | Hash | Set | Zset |
|---|---|---|---|---|
| SDS | LinkedList/ZipList/QuickList | Dict、ZipList | Dict、Intset | ZipList、SkipList |
Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2 之后,引入了 LinkedList 和 ZipList 的结合 QuickList,List 的底层实现变为 QuickList。从 Redis 7.0 开始, ZipList 被 ListPack 取代。
你可以在 Redis 官网上找到 Redis 数据类型/结构非常详细的介绍:
2.1 简单动态字符串(SDS)
String 是一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码 或者解码或者图片的路径)、序列化后的对象
数据结构
struct sdshdr{
// 记录buf中已使用的字节数,即SDS字符串长度
int len;
// 记录buf中未使用剩余的字节数
int free;
// 字节数组,用于保存字符串
char []buf
}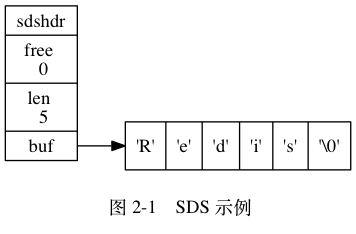
free为 0 ,表示 SDS 没有任何可分配空间len为 5,表示当前存储了 5 个字节长度的字符串buf是 char类型 的数组,数组前五个字节保存了'R'、'e'、'd'、'i'、's'5 个字符,而最后一个字节保留空字符串'\0'
注意:
为啥 len 为 5,是由于 SDS 的内部函数 会自动为结尾默认多分配 1 个字节 \0 ,这样的好处是可以直接重用 C 字符串函数库的函数 ,比如 打印 printf() , 可直接使用 stdio.h/printf 函数
printf("%s", s->buf);
// "Redis"那为啥不直接用 C 的字符串?
- O(1)获取长度: C 的字符串获取长度需要遍历,SDS直接通过
len可以获取到字符串长度; - 避免缓冲区溢出: C 的
<string.h>/strcat拼接时,默认用户已经分配好了空间,一旦未分配则会溢出。而 SDS 的 API 则会先检查容量是否充足,不够就扩展再拼接; - 减少内存重分配开销: C 的字符串
append/trim需要重分配,否则就 缓冲区溢出/内存泄露 。SDS则:- free预分配: 小于1MB,
free = len字节数量,否则每次 free+ 1MB,实际长度为 分配空间 + 1MB + 1byte 从而减少分配次数; - 惰性空间释放: 删减字符串 不立即分配回收,而是用
free记录,便于后续再扩容;
- free预分配: 小于1MB,
- 二进制安全: C 的字符串必须符合某种编码 (如 ASCII) ,而SDS可以用
len来判断字符串结束( 非通过\0) 且 API 都以二进制的方式去处理buf内的数据;
附录
2.2 链表
因为 Redis 使用的 C 语言并 没有内置 这种数据结构, 所以 Redis 构建了自己的链表实现
列表键 (list - key) 的底层实现之一就是链表 ,发布与订阅、慢查询、监视器 等功能也是,Redis 服务器本身还使用链表来 保存多个客户端的状态 信息, 以及使用链表来 构建客户端输出缓冲区(output buffer)
数据结构
定义了 list 结构,来存储 ListNode 双向链表结构的,如下:
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);
} list;
typedef struct listNode {
// 前驱节点
struct listNode *prev;
// 后继节点
struct listNode *next;
// 节点的值
void *value;
} listNode;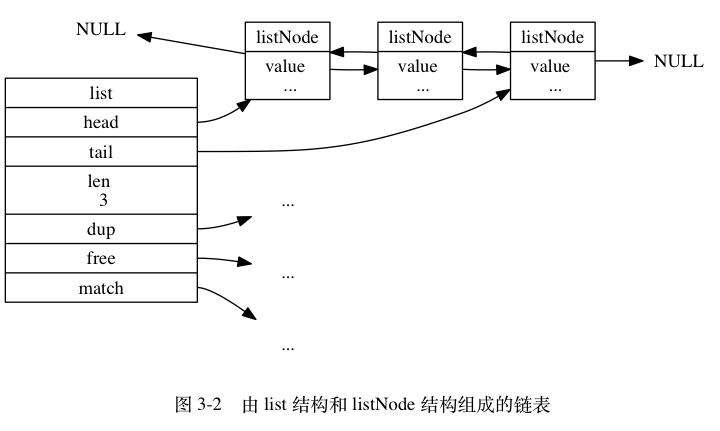
list 结构记录了 头/尾节点、链表长度、特殊函数 ,故它可以实现如下特性:
- 双端: 每个节点都记录了 前驱、后继指针 ,获取复杂度为 O(1)
- 无环
2.2 主要特性
高性能
- 每秒11万次写入
- 每秒8.1万次读取
- 基于哈希表实现的高效查询
数据类型丰富
- 支持多种数据结构
- 便于解决不同应用场景
原子性操作
- 所有操作都是原子性的
- 保证数据一致性
多功能工具
- 缓存
- 消息队列
- 会话管理
- 计数器
2.3
3.1 String操作
# 基本操作
set name igarashi # 设置值
get name # 获取值
keys * # 查看所有键
# 高级操作
set name igarashi ex 3 # 设置3秒过期
set name qwerty nx # 不存在才创建
mset n1 ig n2 ara n3 shi # 批量设置
mget n1 n2 n3 # 批量获取3.2 Hash操作
# 单字段操作
hset info name igarashi # 设置单个字段
hget info name # 获取单个字段
# 多字段操作
hmset info age 22 id huaq2233 # 批量设置
hmget info name age # 批量获取
hgetall info # 获取所有字段和值二、redis:
介绍:
redis 是业界主流的 key-value nosql 数据库之一。和 Memcached 类似,它支持存储的 value 类型相对更多,包括 string(字符串)、list(列表)、
set(集合)、zset(sorted set --有序集合)和 hash(哈希类型)。这些数据类型都支持 push/pop、add/remove 及取交集并集和差集及更丰富的操作,
而且这些操作都是原子性的。在此基础上,redis 支持各种不同方式的排序。与 memcached 一样,为了保证效率,数据都是缓存在内存中。
但是它是可以持久化的,即把数据写在磁盘上:redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现
了 master-slave(主从)同步。
Redis优点
1.异常快速 : Redis是非常快的,每秒可以执行大约110000设置操作,81000个/每秒的读取操作。为什么快?
因为类似字典,把每一个键变为一个hash的值。列表的查找会随着数据的线性增长而增长,而字典则不会。二分的话32次就能查询42亿的数据
因此33次便可以找到世界上的任何一个人。关系型数据库若没建立索引的话就是遍历了,尤其是跨表查询没建立索引老慢了。
2.支持丰富的数据类型 : Redis支持最大多数开发人员已经知道如列表,集合,可排序集合,哈希等数据类型。
这使得在应用中很容易解决的各种问题,因为我们知道哪些问题处理使用哪种数据类型更好解决。
3.操作都是原子的 : 所有 Redis 的操作都是原子,从而确保当两个客户同时访问 Redis 服务器得到的是更新后的值(最新值)。
4.MultiUtility工具:Redis是一个多功能实用工具,可以在很多如:缓存,消息传递队列中使用(Redis原生支持发布/订阅),在应用程序中,
如:Web应用程序会话,网站页面点击数等任何短暂的数据;
安装Redis环境:
要在 Ubuntu 上安装 Redis,打开终端,然后输入以下命令:
$sudo apt-get update
$sudo apt-get install redis-server
这将在您的计算机上安装Redis
启动 Redis:
$redis-server
查看 redis 是否还在运行:
$redis-cli
这将打开一个 Redis 提示符,如下图所示:
redis 127.0.0.1:6379>
在上面的提示信息中:127.0.0.1 是本机的IP地址,6379是 Redis 服务器运行的端口。现在输入 PING 命令,如下图所示:
redis 127.0.0.1:6379> ping
PONG
这说明现在你已经成功地在计算机上安装了 Redis。
Python操作Redis
sudo pip install redis
or
sudo easy_install redis
or
源码安装:
详见:https://github.com/WoLpH/redis-py
在Ubuntu上安装Redis桌面管理器
要在Ubuntu 上安装 Redis桌面管理,可以从 http://redisdesktop.com/download 下载包并安装它。
Redis 桌面管理器会给你用户界面来管理 Redis 键和数据。
三、Redis API 使用
redis-py 的 API 的使用可以分类为:
1.连接方式
2.连接池
3.操作
String 操作
Hash 操作
List 操作
Set 操作
Sort Set 操作
4.管道
5.发布订阅
1、String 操作:
一个name对应一个value
增:set name igarashi
查:get name --"igarashi"
改:set name IGARASHI
查所有:keys *
这看似和python的字典没啥区别呀,NO,python的字典的确看似和它一样,无论从速度等各方面也相同,但是python只能在自己的程序里
假设,你需要把QQ、WPS、Wechat之间的消息进行共享,那么你要给他们两两之间开管道吗?不管道一般适合两两之间的交互,多了不好。此时则可以
利用redis当做但三方交换数据的通道,让它们所有的都从redis中取,把要共享的数据存入redis,redis存在内存因此间接的共享了内存。(都是通过socket)
help set用来查看功能。
set name igarashi ex 3 -- 设置超时3s,3s一过数据不存在。对于不需要长期保留的数据,过期时间显得必要,这比字典强的多(同setex,下同理)
set name qwerty nx -- 不存在才创建。用于统计每个用户的注册到现在的时长,第一次登录创建一个值,此后他就记录用户第一次登录的值。
set name xxxx xx -- 存在才修改。
mset n1 ig n2 ara n3 shi -- 批量修改
mget n1 n2 n3 -- 获取多个值
getset n1 kara -- 获取到旧值,并修改为新值
getrange n1 0 -2 :"kar" -- 切片取值
setrange n1 0 g :"gara" -- 切片设置。当写多了不会扩容而是覆盖后面的值
getbit name 400 -- 表示第400为的二进制的值,没有400位2当然显示0 (显示位数的1或0)假设name为i,那么ord("i") 为 105
bin(105) 为0b1101001 也就是01101001 那么 getbit name 0、1/2/3 的值即为0、1/1/0 ...
setbit name 14 1 -- 把第14位设置为1,这样设置的确是要快,因为字符串是不可变的,你生成一块内存,指向了新的内存,相当于原内存地址的修改。
但是一般人不会这么吹毛求疵。
用途:(若要知道有多少用户登录,分别是哪些用户登录)
假设我有十亿个用户,想要得出当前有多少用户登录了并且每个用户是谁。我可以每次加1加到五亿。此时redis提供一个简单方法的即:
incr n5 -- 每次执行这个命令n5的值++ ,可指定步长
但是分别有哪些用户。(若每一个用户加键值对,那么则有五亿个键值对,耗空间)那就每一个用户登录,拿到用户的userID,它应该是一个数字,
此时设置同样的二进制的第几位为1即可。之后用bitcount -- 统计有多少位是1的。
获取到对应0ASCII码的字符 chr(0) --> \x00 验证此字符是否为0 ord("\x00")
set LOGIN_USERS \x00 -- 注意这种方式不行,它会转义字符串为\\x00 因此可以通过设置 set LOGIN_USERS 0
通过order("0")得出值为48 再利用bin(48)得出0b1100000 之后利用setbit LOGIN_USERS 1/2 0 此时bitcount LOGIN_USERS 为 0
往后每次有新用户登入只用记录userID 如userID=20 则setbit LOGIN_USERS 20 1 让对应的每一位为 1 用bitcount则统计出共有多少用户,
每一位则对应着用户id。查询其userID=32的用户是否登录 get LOGIN_USERS 32 若为1则表示已经登录。用户退出把二进制改为零即可。
这就是可以从系统上提高性能的做法,若从数据库或是查session太慢,因此用这种办法仅用位存一个特别大的字符串,即可实现最省空间的方式存储。
strlen 返回字符串的长度
incrbyfloat n6 1.2 -- 可以小数自增
decr -- 对应自增,即自减 可得到负数
2.Hash操作:
若说String是普通的键值对通过hash的话,那么Hash的key是哈希的,它的值则又对应一个字典。表现形式则更像python的字典,可以存储关联性较强的数据。
比如n1是一个用户 那么里面还可以存姓名、年龄、身份证号(hset key field(字段) value)这种关联性较强的数据
hset info name igarashi hset info age 22 hset info id huaq2233 -- 这样存储一个信息字典
hget info name/age/id -- 则获取对应的值
hkeys info : name、age、id -- 则获取info里面的所有键
hmget info name age :igarashi 22 -- 批量获取到值
hmset info age 22 id huaq2233 -- 批量设置键值对
hgetall info -- 可以获取info下的所有键和值交叉的
但是和info同级的则hash不能看,因为keys * 不能分辨出String和Hash类型,它只能取所有的keys
hlen info -- 获取info的长度
hvals info -- 获取info的所有值,对应hkyes info
hexists info id -- 检测info下的id是否存在,有返回1
hdel info id -- 删除info下的id
hincrby、float info age 1 -- 使info下的age每次自增1,float同
hscan info 0 match a* -- 找到info下所有a开头的键值对。0是游标,不迭代的话用的很少
hscan_iter -- 已迭代的形式取数据,也很少用
3.List操作:
在内存中是按照一个name对应一个List来存储的,和python中 列表一样
lpush names igarashi fuuka kirito kuma fuuka -- 创建一个name列表直接向里面推值,可重复
llen names -- 查看names的长度
lrange names 0 -1 -- 列表的切片,取names的所有值 栈
lpushx names momoko -- 若names列表存在才入栈,注意只能入一个,没有也不报错
linsert names brfore|after igarashi [pivot(标杆值:表示插前面或后面)] fuuka -- 表示在names下的igarashi前后插入值,这里是出栈第一个
lset names 4 igarashi -- 设置出栈第5个的值为igarashi
lrem names 1 igarashi -- 删除出栈后的一个值为igarashi的元素
lpop names -- 出栈,即删除,删没了为空,不报错
lindex names 3 -- 根据索引获取出栈顺序的元素,从零开始
ltrim names 2 5 -- 截取,值保留2~5的这四个值,左右都包
rpoplpush names name3 -- 从names的右侧弹栈向name3的左侧入栈 (注意:通常lpop默认是左侧弹栈)有用
blpop name1 ..name4 40 -- 从name1开始依次弹栈,若没有值则会阻塞,等到在开cli入栈时解除阻塞弹栈。 也有用
brpoplpush name1 name3 40 --从name1的右侧弹栈...并无值阻塞..(多了个超时时间同上)
4.Set集合操作:
Set集合即不允许重复的列表,下面是无序集合
sadd set_n1 igarashi fuu ka fuu -- 把元素放入集合,集合中的元素不可重复
smembers set_n1 -- 获取n1的所有集合值
scard set_n1 -- 显示n1集合的长度
sdiff set_n1 set_n2.. -- 取第一个集合n1和后面的多个集合不相干的元素(即只有第一个集合存在的元素)
sdiffstore set_n3 set_n1 set_n2 -- 把n1中有的且n2中没有的拿出来给n3(同上)
sismembers set_n3 igarashi -- 判断set_n3中是否有igarashi的值
smove set_n3 set_n1 igarashi -- 把set_n3中的igarashi移除并加入到set_n1中
spop set_n1 -- 把set_n1中的igarashi弹栈
srem set_n3 igarashi -- 把n3中的igarashi删除
sinter set_n1 set_n2 -- 取set_n1和set_n2之间的交集,即公共的部分
sunion set_n1 set_n2 -- 取到n1 和 n2 之间的并集,即除了重复之外的所有部分(所有部分,去重)
srandmember set_n2 -- 随机取到n2中的值
sunionstore set_n4 set_n1 set_n2 -- 取n1 和 n2的并集再放入n4中
sscan set_n4 0 match *a -- 取n4中以a结尾的值 0是游标
sscan_iter 同上,用于增量迭代分批获取元素,避免内存消耗太大
有序集合,在无序集合的基础上为每个元素排序,元素排序需要跟另一个值来进行比较。因此对于有序集合,每一个元素有两个值,值和分数(用做排序)
zadd set_z1 10 igarashi -2 fuuka 3 kiri -- 大体同上值指定可以用于排序
zcard set_z1 -- 获取set_z1对应的有序集合元素的数量
zcount set_z1 1 10 -- 获取分数为1~10之间的个数
zincrby set_z1 1 igarashi -- 设置igarashi的分数自增1
zrem set_z1 fuuka -- 删除z1集合中的fuuka,包括分数
zrange set_z1 0 10 -- 获取索引范围在0~10中的元素。额外参数:desc=False, withscores=False, score_cast_func=float
desc,排序规则,默认按照分数从小到大排序
withscores,是否获取元素的分数,默认只获取元素的值
score_cast_func, 对分数进行数据转换的函数
zrank set_z1 igarashi -- 获取igarashi的分数排名,注意是从小到大排,索引为零
zremrangebyrank set_z1 0 1 -- 删除了索引为0到1的元素(根据排行范围删除,全包)
zremrangebyscore set_z1 0 100 -- 删除了分数为0到100之间的元素(根据分数删除)
zscore set_z1 igarashi -- 获取z1 中igarashi的分数
zinterstore: 不进行演示,获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作
zunionstore:同上,获取的是并集 额外参:aggregate=None aggregate的值为: SUM MIN MAX
zscan set_z1 0 match *i -- 获取到i开头的集合包括分数 zscan_iter --基本同上
5.全局操作:
delete(*names)根据删除redis中的任意数据类型 -- 命令行是del
exists(name)检测redis的name是否存在
keys(pattern='*')根据模型获取redis的name
更多:
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
expire(name ,time)为某个redis的某个name设置超时时间
rename(src, dst)对redis的name重命名为
select 1 切换数据库,默认好像是8个
move(name, db))将redis的某个值移动到指定的db下
randomkey()随机获取一个redis的name(不删除)
type(name)获取name对应值的类型
scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None)同字符串操作,用于增量迭代获取key
四、连接方式
1、远程连接:
redis-py 提供两个类 Redis 和 StrictRedis 用于实现 Redis 的命令,StrictRedis 用于实现大部分官方的命令,并使用官方的语法和命令,
Redis 是 StrictRedis 的子类,用于向后兼容旧版本的 redis-py。
1.第一次连接Vmware 发现不通,先ping虚拟机地址ping 192.168.80.133 通的话再telnet 端口,若没有打开则在window功能中打开telnet
2.telnet 192.168.80.133 6379(redis的默认端口) 若不通则说明虚拟机的端口未打开或墙了,此时切换到虚拟机
3.linux下查看防火墙 sudo iptables -L 发现都是accept表示默认全接受,没有防火墙。因此则只能是本身端口没有开放
4.linux下看端口 netstat -tulnp 发现6379端口为本机回环地址127.0.0.1 ,此时表示本机连,改为广播0.0.0.0
5.sudo vim /etc/redis/redis.conf 打开配置文件,通常软件都会安装到etc配置目录中,因此在配置文件中找到bind改为0.0.0.0
(注:vim中查找可以用/bind,退出除了:wq还可以shift+zz)
6.此时用 /etc/init.d/redis-server stop(先停止) start(在开启) restart(或是直接重启)此时netstat -tulnp查看端口更改
import redis
r = redis.Redis(host='10.211.55.4', port=6379)
r.set('foo', 'Bar')
print r.get('foo')
2、配置用户密码:
远程连接不安全因此应该需要密码
1.sudo /etc/redis/redis.conf 用/require 在按n 找到下一个next x删除 i插入更改密码 shift+zz保存
2.sudo /etc/init.d/redis-server restart 重启init.d是一般的所有启动脚本都配置于此
3.本机认证是auth之后直接输密码即 auth igarashi -- OK!
4.之后的python连接通过 r = redis.Redis(host="192.168.80.133", port=6379, password="igarashi", db="1")即可
db则是可以切换数据库
3.连接池(提高数据库性能办法一)
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一
个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
五、管道(提高数据库性能办法二)
redis-py 默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作。如果想要在一次请求中指定多个命令,则可以使用 pipline
实现一次请求指定多个命令,并且默认情况下一次 pipline 是原子性操作。
每次请求数据库,其实都要向连接池申请连接。多次操作就要不断的申请,断开。若要一次性申请多次连接,此时就开一个管道批量申请连接。
pool = redis.ConnectionPool(host='192.168.80.133', port=6379, password="igarashi", db="1") # 开连接池
r = redis.Redis(connection_pool=pool)#此时程序的各个地方都可以共用这个连接池了
# pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True) # 若想要性能更高,开管道,要么都成功要么全失败。像mysql的事务开始
pipe.set('name', 'alex') # 此时就算宕了也不会设置进行,像回滚一样
pipe.set('role', 'sb')
pipe.execute()#只要这句执行,才会set完毕。
这种即是优化redis性能的办法。redis是单线程的,典型的IO多路复用,速度快用的epoll。(select的server端就维持了一个连接)
六、发布订阅:
和 rabbitmq 基本一致。 发布者:服务器。 订阅者:Dashboad 和数据处理
见类redis_helper:
1.先开连接池
2.初始化设置发布订阅的Channels频道
3.发布中调用.publish()传入频道:chan_pub 消息:msg
4.订阅中调用.pubsub()打开收音机,之后.subscribe()传入chan_sub调整频道,.parse_response()开始监听-解析响应
之后public进行发送消息subscribe进行阻塞式的监听,没有数据就卡着。
七、额外操作: 1.持久化周期配置:
在 vim /etc/redis/redis.conf 配置文件中/save 找到 save
出现 save 900 1 见如上注释,900s 存一次,若对数据安全要求高的话,可能 30s 存一次
若要杀死进程 ps -ef |grep redis kill xxxx 此时进程则会自己起来。为啥?
因为有守护进程,发现它宕了就自己起来了。因此判断它有种技术能在这15分钟间进程崩坏保留数据,但应该不会写字磁盘上,即断电丢失。
(实时证明,怕是写在磁盘上了,断电没有丢失)
若要手动的去存-刷磁盘:就直接save一下,则直接保留数据。
八、更多参见:
https://github.com/andymccurdy/redis-py/
http://doc.redisfans.com/
新浪微博:大量使用Redis。好几亿的用户每天大量产生几个T的数据,因此不会在单台RedisServer上,此时便会有Redis集群。
Redis可以搞集群,虽然不需要开发去配置,集群也能作为数据主从备份,都会考虑安全之类的这些问题。codereview