Mysql调优
MYSQL 机制详解
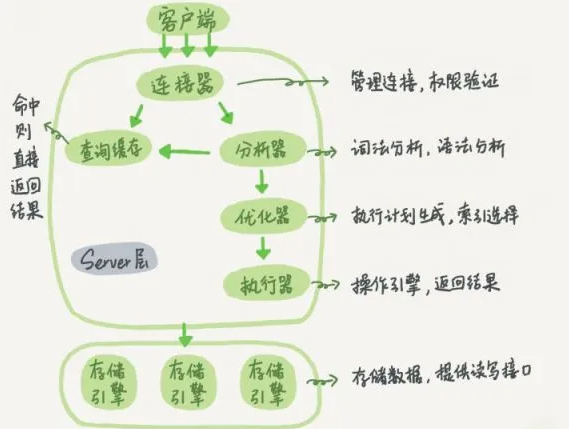
MySQL 执行查询的过程
- 客户端通过 TCP 连接发送连接请求到 MySQL 连接器,连接器会对该请求进行权限验证及连接资源分配
- 查缓存。(当判断缓存是否命中时,MySQL 不会进行解析查询语句,而是直接使用 SQL 语句和客户端发送过来的其他原始信息。所以,任何字符上的不同,例如空格、注解等都会导致缓存的不命中。)
- 语法分析(SQL 语法是否写错了)。 如何把语句给到预处理器,检查数据表和数据列是否存在,解析别名看是否存在歧义。
- 优化。是否使用索引,生成执行计划。
- 交给执行器,将数据保存到结果集中,同时会逐步将数据缓存到查询缓存中,最终将结果集返回给客户端。
引擎:
- InnoDB: 插入时按主键排序插入(最常用) -- 聚集
- MYISAM: 按照插入时顺序插入 -- 堆表(数据堆在一起)
一、InnoDB 存储结构
1. 页存储机制
- 操作系统内存页:4KB
- InnoDB页大小:默认16KB (
innodb_page_size = 16384)
页结构组成:
File Header
Page Header
Infimum + Supremum Records
User Records
Free Space
Page Directory
File Trailer2. InnoDB行格式
| 行格式 | 特点 | 适用场景 |
|---|---|---|
| Compact | 变长字段长度列表 + NULL标志位 + 记录头信息 + 列数据 | 常规使用 |
| Redundant | 兼容老版本 | 历史遗留系统 |
| Dynamic | 行溢出数据全部存储到其他页面,只保留地址 | 大字段数据 |
| Compressed | 在Dynamic基础上增加页面压缩 | 存储敏感场景 |
设置语法:
CREATE TABLE 表名 (列信息) ROW_FORMAT=行格式名称;
ALTER TABLE 表名 ROW_FORMAT=行格式名称;3. 行存储特性
- 行大小限制:非BLOB字段最大65535字节
- 隐藏列:
DB_ROW_ID(6B):无主键时自动生成DB_TRX_ID(7B):事务IDDB_ROLL_PTR(7B):回滚指针
- 行溢出处理:
- 方式1:当前页存部分数据+下一页地址
- 方式2:只存起始页和末尾页地址(与索引相关)
二、索引机制
1. B+树索引结构
根节点(非叶子节点)
↓
中间节点(非叶子节点,存储主键+指针)
↓
叶子节点(存储实际数据)特点:
- 非叶子节点仅存储键值和指针
- 叶子节点形成有序链表,支持高效范围查询
- 每个节点可存储多个元素(相比二叉树高度更低)
2. 索引存储计算
- 假设主键为BIGINT(8B),指针6B
- 单页可存储键值对:16KB/(8+6) ≈ 1170
- 高度为3的B+树可存储:1170×1170×16 ≈ 2千万条记录
3. 索引使用原则
辅助索引(二级索引)
- 额外构建B+树,叶子节点存储主键值
- 查询流程:辅助索引→主键索引→数据(回表)
最左前缀原则
联合索引(b,c,d)只能匹配:
WHERE b=1 AND c=1 AND d=1(完全匹配)WHERE b=1 AND c=1(部分匹配)WHERE b LIKE '101%'(前缀匹配)
不匹配:
WHERE c=1 AND d=1WHERE b LIKE '%101%'
索引优化技巧
- 后缀匹配优化:
LIKE '%com'→ 存储逆序moc% - NULL值在索引中视为最小值
- 相同值的非唯一索引会附加主键值
页目录: 本质是树,即用一个页 利用二分法进行来记录各数据的地址,每一页会有主键,并把主键提出来作为索引部分
页号100 页号200
1 -> 1111a 5 -> 5555e
2222b -> 6666f
3 -> 3333c... 7 -> 7777g ...目录页:
额外提出一个页,用来存储页号,但每一页的页号可不是相邻的,反而会再用一个 key-value 去存储页号
1 5 -- 主键
100 200 -- 指针
| |
页号100 页号200 -- 指针指向的行数据
- **key:**每页中最小的值, 利用主键都是递增顺序排列
- **value:**对应的页号
因此就是一个B+树结构(根节点的元素总会留一个在叶子节点上) 一个节点也可以存多个元素
0003 0005
| | |
0002 0004 0005
| | | | | |
0001 -> 0002 -> 0003 -> 0004 -> 0005 -> 0006 0007叶子节点:存数据
非叶子节点:存主键 + 指针
所以插入索引的过程中是生成B+树的过程,这就是为什么有序的原因,是存在了B+树的叶子节点里
注:
1.主键ID不适合太长,若过于长的话一页放不下,再会将树的高度拉长,树的高度越高,查找速度就会下降
2.mysql 创建过程略微不同,他是当执行创建表命令时,就会创建一个页,当一个页装不下后,不是在创建第二个页,
而是将第一个页copy一份,创建第二个页,再将之前的第一页改为目录页
3.B+树的优势,相比于AVL树(二叉) B+树的优势在于一个节点可以存多个元素,因此会比AVL树高度要低,因此查找
时的执行效率要低。虽然数据冗余了,查找 = 等于的条件不明显,但查找> < 条件时则不同
例如: 查 > 0002 的数据,可以直接利用索引(0002后的链表指针)提取所有数据,而AVL树要先找出右子树
的节点,之后还要回归父节点,层层遍历 (SQL范围查询)
据说 B+树高度等于2 的时候,大约可存 20000多条数据, B+树高度等于3 的时候, 可以存 2千万多条数据
假设推算:主键用bigint类型 占8字节 指针占6个字节 因此在一页中,可以存多少个非叶子节点
16kb/(8+6)=1170.28... 可以存1170对 键值对(代表下面有多少个叶子节点)
此时假设一行数据为1KB,一页存16条数据,那么高度为2的情况下 可存 1170 * 16 = 18724 条数据
因此用B+树找最多找两次就能在2千多万条数据中找到那个页基本结构
- 本质:一种优化页内数据查找的二分搜索结构
- 位置:位于每个数据页的尾部(Page Directory区域)
- 组成:
- 槽位(Slots):存储每组记录的最大主键值
- 指针:指向对应记录组的起始位置
工作流程
数据页内部结构:
+---------------------+
| 记录1 (ID=1) |
| 记录2 (ID=3) |
| 记录3 (ID=5) |
| ... |
+---------------------+
| 页目录 |
| Slot1: ID=5 -> 记录3 |
| Slot2: ID=3 -> 记录2 |
| Slot3: ID=1 -> 记录1 |
+---------------------+查找过程(以查找ID=4为例):
- 通过二分查找确定ID=4位于Slot1(ID=5)和Slot2(ID=3)之间
- 根据指针定位到记录组(记录2到记录3之间)
- 在组内线性查找目标记录
2. B+树索引的完整结构
层级关系示例
根节点(页号300)
+---------------+
| 键值: 5 | → 指向页200
| 键值: 10 | → 指向页250
+---------------+
↓
中间节点(页200) 中间节点(页250)
+---------------+ +---------------+
| 键值: 3 | → | 键值: 7 | →
| 键值: 5 | → | 键值: 10 | →
+---------------+ +---------------+
↓ ↓
叶子节点(页100) 叶子节点(页150) 叶子节点(页300)
+---------------+ +---------------+ +---------------+
| 1 → 记录A | | 5 → 记录E | | 10 → 记录J |
| 2 → 记录B | | 6 → 记录F | | 11 → 记录K |
| 3 → 记录C | | 7 → 记录G | | ... |
+---------------+ +---------------+ +---------------+关键特性
双向链表连接:所有叶子节点通过指针形成双向链表,支持高效范围查询
页100 → 页150 → 页300 → ...填充因子:每个节点通常填充15/16的空间(约93.75%)
分裂规则:
- 当页满时发生分裂
- 中间键值会上提到父节点
- 示例:页150满时分裂为页150和页155,键值7上提到父节点
3. 索引操作示例
查找ID=6的记录
- 从根节点(页300)开始:
- 6 < 10 → 选择左分支(页200)
- 在页200中:
- 3 < 6 ≤ 5 → 选择页150
- 在页150中线性查找找到ID=6的记录F
范围查询ID BETWEEN 4 AND 8
- 定位到ID=4的起始位置(页150)
- 沿叶子节点链表扫描:
- 页150:5(E), 6(F), 7(G)
- 页300:...(直到ID>8停止)
4. 与哈希索引的区别
| 特性 | B+树索引 | 哈希索引 |
|---|---|---|
| 查询类型支持 | 等值、范围、排序 | 仅等值查询 |
| 磁盘I/O效率 | 高(顺序访问) | 随机访问 |
| 内存利用率 | 高(节点可缓存) | 依赖哈希表大小 |
| 适合场景 | OLTP/OLAP | 内存表/缓存 |
5. 实际优化案例
问题:某电商平台商品表查询缓慢
解决方案:
-- 原结构
CREATE TABLE products (
id BIGINT PRIMARY KEY,
name VARCHAR(100),
category_id INT,
price DECIMAL(10,2)
);
-- 优化方案
ALTER TABLE products
ADD INDEX idx_category_price (category_id, price),
ADD INDEX idx_name (name);
-- 查询优化
SELECT * FROM products
WHERE category_id = 5
ORDER BY price DESC
LIMIT 20; -- 现在可以利用联合索引直接定位效果:
- 查询时间从1200ms降至15ms
- 磁盘I/O减少80%
- 内存缓存命中率提升至95%
三、事务机制
1. ACID特性
| 特性 | 保证机制 | 实现原理 |
|---|---|---|
| 原子性 | Undo Log | 回滚未提交事务 |
| 隔离性 | 锁/MVCC | 控制并发访问 |
| 持久性 | Redo Log | 故障恢复 |
| 一致性 | 以上三者共同保证 | 业务规则约束 |
2. 事务控制语句
BEGIN/START TRANSACTION; -- 开启事务
COMMIT; -- 提交事务
ROLLBACK; -- 回滚事务
SAVEPOINT 名称; -- 创建保存点
ROLLBACK TO 名称; -- 回滚到保存点
RELEASE SAVEPOINT 名称; -- 释放保存点3. 隔离级别对比
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 实现机制 |
|---|---|---|---|---|
| READ UNCOMMITTED | 可能 | 可能 | 可能 | 无防护 |
| READ COMMITTED | 不可能 | 可能 | 可能 | MVCC快照读 |
| REPEATABLE READ | 不可能 | 不可能 | 可能* | MVCC+间隙锁 |
| SERIALIZABLE | 不可能 | 不可能 | 不可能 | 完全串行化 |
记忆技巧
可以这样记忆:
- 隔离级别名称描述的是它保证什么,而不是它禁止什么
- 保证的内容越多,隔离级别越高
| 隔离级别 | 保证内容 |
|---|---|
| READ COMMITTED | 只读已提交的数据 |
| REPEATABLE READ | 读已提交的数据 + 同一事务内多次读取结果一致 |
关于 REPEATABLE READ 和幻读
MySQL 的 InnoDB 在 REPEATABLE READ 隔离级别下,通过 间隙锁 解决了部分幻读,但没有完全解决快照读下的幻读问题
可以做这个实验:
- 当前DB已有id 5, 10, 15三条数据。
- 事务A查询id < 10的数据,可以查出一行记录id = 5
- 事务B插入id = 6的数据
- 事务A再查询id < 10的数据,可以查出一行记录id = 5,查不出id = 6的数据(读场景,解决了幻读)
- 事务A可以更新/删除id = 6的数据,不能插入id = 6的数据(写场景,幻读不彻底)
实验场景复现
-- 初始数据
INSERT INTO test VALUES (5), (10), (15);
-- 事务A
BEGIN;
SELECT * FROM test WHERE id < 10; -- 看到id=5
-- 事务B
BEGIN;
INSERT INTO test VALUES (6);
COMMIT;
SELECT * FROM test WHERE id < 10; -- 仍只看到id=5(快照读防幻读)
-- 但可以执行以下操作:
UPDATE test SET val=1 WHERE id=6; -- 能更新"幻影行"!
DELETE FROM test WHERE id=6; -- 能删除"幻影行"!这个很好理解,**MySQL **虽然通过 MVCC 的版本号来解决了读场景下的幻读,但对于上面 第5步 那种写场景的情况,其实是无能为力的,因为 MVCC 毕竟是无锁实现。
MySQL防幻读机制的两面性
| 防护类型 | 机制 | 效果 | 局限性 |
|---|---|---|---|
| 读防护 | MVCC快照 | 同一事务内相同查询返回一致结果 | 仅适用于SELECT查询 |
| 写防护 | 间隙锁 | 阻止其他事务插入间隙数据 | 只在使用锁操作时生效 |
为什么会出现这种"半解决"状态?
# 技术根源: MVCC简化实现原理
class InnoDB:
def __init__(self):
self.version_chain = {} # 存储所有版本数据
def read(self, transaction_id):
# 只读取版本号<=事务ID且已提交的数据
return [v for v in self.version_chain
if v.version <= transaction_id
and v.committed]
def write(self, transaction_id):
# 写入时不检查其他事务的快照视图
self.version_chain.append(NewVersion(transaction_id))关键点:
- 读操作基于事务开始时的 ReadView
- 写操作基于当前最新数据
- 这种读写分离的设计导致了现象不一致
生产环境解决方案
方案1: 后续要对数据进行写操作,强制使用锁查询
-- 安全写法(彻底防幻读) SELECT * FROM table WHERE condition FOR UPDATE;方案2: 乐观锁控制
# Python示例(使用版本号) row = session.execute("SELECT id, version FROM table WHERE id=1").fetchone() # 业务处理... affected = session.execute( "UPDATE table SET value=?, version=version+1 WHERE id=? AND version=?", [new_value, row.id, row.version] ) if affected.rowcount == 0: raise Exception("并发修改冲突")方案3: 合理设计事务
/* 好的实践 */ BEGIN; -- 所有查询都加锁 SELECT * FROM ... FOR UPDATE; UPDATE ...; COMMIT; /* 危险实践 */ BEGIN; SELECT * FROM ...; -- 不加锁的快照读 UPDATE ...; -- 可能操作幻影行 COMMIT;
为什么敢用READ COMMITTED?
有补偿措施:
监控系统实时检测异常数据
# 伪代码:定期校验数据一致性 def consistency_check(): with db.transaction(isolation='READ COMMITTED') as tx: data1 = tx.execute("SELECT COUNT(*) FROM orders") # 业务处理... data2 = tx.execute("SELECT COUNT(*) FROM orders") if data1 != data2: alert("发现不可重复读现象")- 关键操作使用显式锁
- 通过业务逻辑设计规避问题
理解本质:
MySQL 的 RR 是"80分解决方案",不是100% 防幻读
# 好的代码注释示例 def update_inventory(item_id): """库存更新方法 注意:使用SELECT FOR UPDATE确保防幻读 """ with transaction(isolation='REPEATABLE READ'): row = session.execute( "SELECT * FROM inventory WHERE item_id=? FOR UPDATE", [item_id] ) # ...业务逻辑
这种设计其实是工程上的权衡——在保证大部分场景可用的前提下,把复杂情况交给开发者显式处理,既获得了性能提升,又把控制权交给了最了解业务的人。
4. MVCC机制
- 版本链:通过
DB_TRX_ID和DB_ROLL_PTR构建 - ReadView:包含:
m_ids:活跃事务列表min_trx_id:最小活跃事务IDmax_trx_id:预分配最大事务IDcreator_trx_id:创建该ReadView的事务ID
不同隔离级别的ReadView生成策略:
- READ COMMITTED:每次SELECT生成新ReadView
- REPEATABLE READ:第一次SELECT生成ReadView后复用
四、锁机制
1. 锁类型矩阵
| 锁类型 | X锁(排他) | S锁(共享) | IS锁(意向共享) | IX锁(意向排他) |
|---|---|---|---|---|
| X锁 | 冲突 | 冲突 | 冲突 | 冲突 |
| S锁 | 冲突 | 兼容 | 兼容 | 冲突 |
| IS锁 | 冲突 | 兼容 | 兼容 | 兼容 |
| IX锁 | 冲突 | 冲突 | 兼容 | 兼容 |
2. InnoDB锁算法
| 锁算法 | 锁定范围 | 解决什么问题 |
|---|---|---|
| Record Lock | 单个行记录 | 保证行更新安全 |
| Gap Lock | 记录之间的间隙 | 防止幻读 |
| Next-Key Lock | 记录+前间隙 | 防止幻读(默认) |
3. 不同隔离级别的锁行为
READ COMMITTED:
- 仅使用Record Lock
- 可能出现幻读
REPEATABLE READ:
- 默认使用Next-Key Lock
- 基本解决幻读问题
- 全表扫描会锁全表
4. 乐观锁与悲观锁对比
| 特性 | 悲观锁 | 乐观锁 |
|---|---|---|
| 原理 | 先加锁后访问 | 版本号/时间戳校验 |
| 实现 | SELECT...FOR UPDATE | 应用层实现 |
| 优点 | 保证强一致性 | 高并发性能 |
| 缺点 | 锁开销大 | 重试成本高 |
| 适用 | 写多读少 | 读多写少 |
乐观锁实现示例:
# 需要设置隔离级别为READ COMMITTED
@transaction.atomic
def update_inventory():
for i in range(5): # 最大重试5次
product = Product.objects.get(id=1)
old_stock = product.stock
new_stock = old_stock - 1
affected = Product.objects.filter(
id=1, stock=old_stock
).update(stock=new_stock)
if affected:
break # 更新成功
else:
raise Exception("更新失败")五、SQL优化建议
字段设计:
- 使用合适的数据类型
- 尽量设置NOT NULL
- 枚举类型使用ENUM
查询优化:
- 用JOIN代替子查询
- 用UNION代替临时表
- 合理使用索引
事务优化:
- 缩短事务执行时间
- 避免长事务
- 合理设置隔离级别
锁优化:
- 尽量使用行锁而非表锁
- 访问量大的系统考虑READ COMMITTED
- 关键业务使用SERIALIZABLE
三、索引:
页目录:
本质是树,即用一个页 利用二分法进行来记录各数据的地址,每一页会有主键,并把主键提出来作为索引部分页号100 页号200 1 -> 1111a 5 -> 5555e 2222b -> 6666f 3 -> 3333c... 7 -> 7777g ... 目录页: 额外提出一个页,用来存储页号,但每一页的页号可不是相邻的,反而会再用一个 key-value 去存储页号 1 5 -- 主键 100 200 -- 指针 | | 页号100 页号200 -- 指针指向的行数据 key:每页中最小的值, 利用主键都是递增顺序排列 value:对应的页号 因此就是一个B+树结构(根节点的元素总会留一个在叶子节点上) 一个节点也可以存多个元素 0003 0005 | | | 0002 0004 0005 | | | | | | 0001 -> 0002 -> 0003 -> 0004 -> 0005 -> 0006 0007 叶子节点:存数据 非叶子节点:存主键 + 指针 所以插入索引的过程中是生成B+树的过程,这就是为什么有序的原因,是存在了B+树的叶子节点里 注: 1.主键ID不适合太长,若过于长的话一页放不下,再会将树的高度拉长,树的高度越高,查找速度就会下降 2.mysql 创建过程略微不同,他是当执行创建表命令时,就会创建一个页,当一个页装不下后,不是在创建第二个页, 而是将第一个页copy一份,创建第二个页,再将之前的第一页改为目录页 3.B+树的优势,相比于AVL树(二叉) B+树的优势在于一个节点可以存多个元素,因此会比AVL树高度要低,因此查找 时的执行效率要低。虽然数据冗余了,查找 = 等于的条件不明显,但查找> < 条件时则不同 例如: 查 > 0002 的数据,可以直接利用索引(0002后的链表指针)提取所有数据,而AVL树要先找出右子树 的节点,之后还要回归父节点,层层遍历 (SQL范围查询) 据说 B+树高度等于2 的时候,大约可存 20000多条数据, B+树高度等于3 的时候, 可以存 2千万多条数据 假设推算:主键用bigint类型 占8字节 指针占6个字节 因此在一页中,可以存多少个非叶子节点 16kb/(8+6)=1170.28... 可以存1170对 键值对(代表下面有多少个叶子节点) 此时假设一行数据为1KB,一页存16条数据,那么高度为2的情况下 可存 1170 * 16 = 18724 条数据 因此用B+树找最多找两次就能在2千多万条数据中找到那个页 辅助索引: 出了主键索引之外,创建的普通索引。好处在于更方便查找,但走辅助索引会走两次,因为建立辅助索引意味着全表 又重新构建了一颗B+树,子节点存的是主键,走辅助索引会先找到主键在去主键表中找数据。 例: create index idx_t1_bcd on t1(b,c,d); 创建名为idx_t1_bcd的索引,bcd三列必须唯一且会进行排序,并再次生成一个已bcd为 键的B+树 查找方式: 1.辅助索引+ 回表 2.全表扫描 但当一个比较极端的情况,走辅助索引吧全表的主键都找了一遍,此时还不如走全表索引来得快: create index idx_t1_b on t1(b); -- 此时只建立一个b的索引(上文索引无) explain select * from t1 where b > 0; 此时 若走辅助索引还不如走主键全表扫描来的快 因为 b > 0 这个条件吧主键索引都找了出来,又去全表索引再找一遍,这就很慢。 最左前缀原则: 当建立 bcd 三列的索引时, explain select * from t1 where b = 1 and c = 1 and d = 1; -- 命中索引 explain select * from t1 where c = 1 and d = 1; -- 未命中 若数据从 111 到 644 *11 是没有办法进行比较的,第一个值不知道因此未走索引 111 644 页号 页号 | | 111 235 322 644 explain select * from t1 where b like '%101%'; -- 未命中索引 同上 % 在开头也意味着 第一个值是模糊的,开头可以是多个,而 '101%' 则可以 注: 1.用上文的道理,若要查找已.com 为后缀结尾的 用 %com,则会全表扫描, 可以将 www.baidu.com 、www.google.com 这样的网站逆序存储,然后利用 %moc 进行查找 则可直接命中索引 select * from t1 order by b,c,d; -- 走全表 select b from t1 order by b,c,d; -- 命中索引 这是因为 只找一个b字段,b字段本身有索引,因此就无须再走一次全表了 2.NULL 值在MYSQL中小于任何值 3.若其他索引有相同的数据(不是唯一索引),则系统会默认将主键索引也加入B+树的构成中,便于区分
MYSQL 事务:
一、事务(ACID)
场景:小明向小胖转账10块钱
原子性:转账操作是一个不可分割的操作,要么转账失败,要么转账成功,不可能存在中间状态,也就是转了一半的这种情况
我们把要么全做要么不做这种的规则成为原子性规则
隔离性:
另一个场景:小明向小白转账10元钱
小明向小胖转账10元钱
隔离性表示上面的两个操作是不能相互影响的
一致性:
每一次转账完成后,都需要保证整个系统余额等于所有账户的收入减去所有账户的支出。
若不遵循原子性,也就是如果小明向小胖转账10元,但是只转了一半,小明账户上少了10元,小胖账户上没有增加,
这就是不满足一致性原则。
同样不满足隔离性,也有可能破坏一致性。因此原子性和隔离性都是保证满足一致性的手段。
实际上,我们可以对表建立约束来保证一致性。
持久性:
对于转账的交易记录,需要永久保存。
事务的概念:
把需要保证原子性、隔离性、一致性、和持久性的一个或多个数据库操作称之为一个事务。
二、自动提交:
mysql> SHOW VARIABLES LIKE 'autocommit'; -- 正常情况下,MYSQL默认事务是ON 自动提交的
自动提交意味着: 当写一个update之类的语句时,
- 它会先帮我开启一个事务,
- 再去执行我写的SQL
- 再去把这个事务提交上去
1、开启事务
mysql> BEGIN; -- 手动开启一个事务
mysql> START TRANSACTION; -- 和BEGIN功效相同,都是开启一个事务
1.当开启两个MYSQL客户端是,客户端1 执行语句
update t1 set c = 2 where a = 1 ; -- 目的是把a = 1 这行数据的c字段的值改为 2
2.此时在客户端2 上执行
select * from t1 where a = 1; -- 发现客户端2 中查询到的数据并没有改变
3.这时在 客户端1 执行 commit; 提交一下,客户端2 中才能真正查到改动后的数据。
但客户端1 则自己改的自己可以查到。
4.若此时客户端1 上执行rollback 则会进行回滚,之前改动的数据则会改回。
注:rollback 是我们程序员手动去回滚事务时才去使用的,若事务在执行过程中遇到了某些错误而无法继续执行的
话,事务自身会回滚。
三、隐式提交:
当使用 begin 或 start transaction 开启一个事务,或者把系统变量autocommit 的值设置为OFF 时,事务就不会进行自动
提交,但是我们输入了某些语句之后会悄悄的提交掉,就像我们输入了commit 语句一样,这是因为某些特殊的语句而导致事务
提交的情况称为隐式提交。
导致隐式提交的语句包括:
- 定义或修改数据库对象的数据定义语言(Data definition language 缩写:DDL)数据库对象 —— 是指数据库、表、
视图、存储过程、等等这些东西。当我们使用 create、alter、drop等语句去修改这些所谓的数据库对象时,就会隐式的
提交前边语句所属于的事务。
- 隐式使用或修改mysql 数据库中的表; 当我们使用 alter user 、create user、drop user、grant、 rename user、
set password 等语句时也会隐式的提交前边语句所属于的事务。
- 事务控制或关于锁定的语句:当我们在一个事务还没提交或者回滚时就又使用start transaction 或者begin 开启了
另一个事务时,会隐式的提交上一个事务,或者当前的autocommit 系统变量为OFF,我们手动把它调为ON时,也会隐式
的提交前边语句所属的事务,或者用LOCK TABLES、 UNLOCK TABLES 等关于锁定的语句也会隐式的提交前边的语句所属
的事务。
- 加载数据的语句:比如我们使用LOAD DATA 语句来批量往数据库中导入数据时,也会隐式的提交前边语句所属的事务。
- 其他的一些语句:使用analyze table、 cache index、 check table、flush、 load index into cache、
optimize table、 repair table、 reset 等语句也会隐式的提交前边语句所属的事务。
(更新查询优化器的统计数据的命令)
四、保存点:
mysql> savepoint 保存点名称:
- 首先,开启一个事务:
begin
- 然后执行更改命令:
update t1 set c = 6 where a = 1;
- 再执行保存点命令:
savepoint t123
- 再改
update t1 set c = 7 where a = 1;
- 执行回滚
rollback to t123; -- rollback [WORK] to [savepoint] 保存点名称;
若rollback 后面不跟随保存点名称的话,会直接回滚到事务执行之前的状态。
- 删除保存点:
release savepoint 保存点名称;
五、隔离性详解 !!
一共有四种隔离级别:
mysql> set session transaction isolation level read uncommitted; -- 修改隔离级别为(读未提交)
mysql> select @@tx_isolation;
1.读未提交(read uncommitted)
一个事务可以读到其他事务还未提交的数据,会出现脏读。
> 一个事务读到了另一个事务修改过但未提交的数据,即为脏读。
用的少,违背事务的特性,不严谨
2.读已提交(read committed)
一个事务只能读到另一个事务修改过并已提交的数据,并且其他事务每对改数据进行一次修改并提交后,该事务都能查询到
最新值,会出现不可重复读、幻读。
> 如果一个事务先根据某些条件查询出一些记录,之后另一个事务又向表中插入了符合这些条件的记录(并提交),原先的
事务再次按照该条件查询时,能把另一个事务插入的记录也读出来,这就是幻读。
3.可重复读(repeatable read)
一个事务第一次读过某条记录后,即使其他事务修改了该记录的值并且提交,该事务之后再读该条记录时,读到的仍是第一次
读到的值,而不是每次都读到不同的数据,这就是可重复读,这种隔离级别解决了不可重复,但是还是会出现幻读。
也就是客户端1 尽管commit 客户端2 也读不到客户端1 commit 后的值 (其实按理说不会出现幻读了,但也可能发生)
(MYSQL默认的隔离级别 就是可重复读)
4.串行化(serializable)
以上三种隔离级别都允许对同一条记录同时进行读-读、 读-写、 写-读、的并发操作,如果我们不允许读-写、 写-读
的并发操作,可以使用serializable 隔离级别,这种隔离级别因为对同一条记录都是串行的,所以不会出现脏读、幻读
等现象
这中隔离方式,用的也不多,它会在一个客户端 的事务尚未操作commit 时阻塞其他的事务进行查找
注:
1.这四种隔离级别是SQL定义的标准,不同数据库会有不同的实现,特别需要注意的是 [MYSQL 在 repeatable read 隔离
级别下,是可以禁止幻读问题的发生]
2.幻读:本质和不可重复度差不多,幻读只的是多读出了另一个事务生成的一行记录,而不可重复读,指的是读某个记录的
原本字段发生变化
六、事务ID及回滚指针
1.事务id:
如上文提到,mysql除自定义数据外,还有三个隐藏列,行id、事务id、回滚指针
每一次数据进行改动时,都要开启一个事务,因此这行的其中一个隐藏列会记录当时修改的事务id
2.回滚指针:
当修改了一次数据,不仅会修改事务id,还有回滚指针记录上个版本的数据(像链表,存在日志中)
如:
数据 事务id 回滚指针
1 5 1 1 a2 a3 300 trx_id_roll_pointer ____
____________________________________________________|
| 1 4 1 1 a2 a3 200 trx_id_roll_pointer ____
____________________________________________________|
|——>1 3 1 1 a2 a3 82 trx_id_roll_pointer ____
____________________________________________________|
|——>1 2 1 1 a2 a3 81 trx_id_roll_pointer....
3.版本链:
以上为某一行数据的版本链,对于innodb来说,聚簇索引记录中都包含两个必要的隐藏列,(row_id 并不是必要的,我们
创建的表中有主键或者非NULL唯一键时都不会包含row_id列)
trx_id:每次对某条记录进行改动时,都会把对应的事务id赋值给trx_id 隐藏列
roll_pointer:每次对某条记录进行改动时,这个隐藏列会存一个指针,可以通过这个指针找到记录修改前的信息
注:事务回滚的依据是 undolog (后面提)
4.read view:
场景:A事务(id 300) 读取某一列值为 1 B事务(id 200) 修改某一列值为 2
对于A事务在 select 读的时候会生成一个read view (里面会有一个重要属性 m_ids)
m_ids:[] -- 里面保存了活跃的事务id (还未提交的) [82, 200, 300]
- 当A事务未提交时:
会用事务id列表去版本链比对,判断对应事务是否是活跃的,若是,则不去里面找,直到找到不活跃的(已经
提交了的事务,因此会把之前提交过的事务 81 对应的数据给找出来)[82, 200, 300]
- 当A事务已经提交:(读已提交下)
和上述类似,但由于A已经提交,则会根据A事务id 300把对应数据读出[82, 300]
- 当A事务已提交:(可重复读)
m_ids = [82, 200, 300] 此时与上面不同,不会把200 去掉,会直接用第一次select 事,算出来的
read view 会直接去复用read view 即A事务未提交前的read view 。所以最后还是把81 找出的来。
区别:在于生成read view 的时机不同,读已提交,是每次select 都会生成新的read view,
可重复读则是,只在第一次生成read view 之后都沿用这个 read view
5.MVCC总结:
MVCC(multi-version concurrency control,多版本并发控制)指的是 读已提交、可重复读这两中隔离级别
的事务在执行普通的select 访问版本链的过程,可以使不同事务的读-写、写-读操作并发执行,从而提升系统性能。
(避免使用锁,等释放的低效率行为)
七、锁
0.概念图:
——————————————————————— 表锁
乐观锁 —————————————— |
———— 加锁机制 锁粒度 —————————————————————————————— 行锁
悲观锁 —————————————— | | |
———————————————————————— 页锁
———————— 锁 ————————
共享锁 ———————————— ———Record Lock(单个记录上锁)
| | | |
排他锁 ———————————— ———— 兼容性 锁算法 ———————Gap Lock(间隙锁,解决幻读)
| |
意向锁 ———————————— ———Next-Key Lock:Gap Lock+Record Lock
1.读锁和写锁
读锁:共享锁,shared locks S锁。
写锁:排他锁,exclusive locks X锁。(一个资源上加了写锁,其他若需要加锁则需要排队)
select:不加锁(可以跳过锁去访问)
读操作:对于普通的select 语句,InnoDB不会加任何锁
2.select ...lock in share mode
将查找到的数据加上一个S锁,允许其他事务继续获取这些记录的S锁,不能获取这些记录的X锁(会阻塞)
场景:读出数据后,其他事务不能修改,但是自己也不一定能修改,因为其他事务也可以使用" select ...lock
in share mode" 继续加读锁。
3.select ...for update
将查找到的数据加上一个X锁,不允许其他事务获取这些记录的S锁和X锁。
使用场景:读出数据后,其他事务既不能写,也不能加读锁,那么就导致只有自己可以修改数据。
4.写操作:
DELETE:删除一条记录,会先对记录加X锁,再执行
INSERT:插入一条记录,会先加"隐式锁"来保护这条新记录在本事务提交前不被其他事务访问到。
UPDATE:
- 如果被更新的列,修改前后没有导致存储空间的变化,那么会先给记录加X锁,再直接对记录进行修改。
- 如果被更新的列,修改前后导致存储空间发生了变化,那么后先给记录加X锁,然后再将记录删掉,再
insert一条新纪录。
隐式锁:一个事务插入一条记录后,还未提交,这条记录会保存本次事务id,而其他事务如果想来对这个记录加锁
时会发现事务id 不对应,这时会产生X锁,所以相当于在插入一条记录时,隐式的给这条记录加了一把隐式的X锁。
注:
> 事务提交或结束后,锁才会自动进行释放。
> 锁必须是在事务里面才用的。 因为平时开启是个事务不会手写begin、commit ,而是直接写sql,
如:select * from t1 where a = 1 for update ;
但要下意识知道,写这些sql的时候,会默认的先开启一个事务,而再来执行这个sql,然后再提交这个sql。
5.行锁(锁算法)
LOCK_REC_NOT_GAP: 单个行记录上的锁
LOCK_GAP: 间隙锁,锁定一个范围,但不包括记录本身,GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读
的情况
LOCK_ORDINARY: 锁定一个范围,并且锁定记录本身对于行的查询,都是采用该方法,主要目的是解决幻读的问题。
6.read committed 级别下的锁:
- 当用主键查询时
select * from t1 where a = 1 for update;
再开启事务2,进行与上同样对 a = 1 的查询,此时会发现会阻塞。可若进行 a = 2 的主键查询则不会阻塞。
这说明,事务1 利用主键查询,只会锁住查出来的这一行数据
- 当用唯一索引查询时:
与上文其实是一致的,
- 当查询使用普通索引时:
select * from t1 where e = "b" for update; -- 此时查出多条e = "b"的数据
再开启事务2,但执行 a = 1 的主键查询(a = 1 的那条数据 e也等于"b")发现事务2也会阻塞,但若找一个
a = 6 这种(e 不等于 "b")的数据,发现没有阻塞。
这说明,普通索引,会对他查询出来的结果加锁。
此时执行 insert t1(b, c, d, e) values(30, 1, 1, "b"); 插入数据,是可以进行插入e = "b"相关数据的。
- 当全表扫描时:(未使用索引)
其实同上,并不会锁住全表,也只会将事务1查询出来的数据锁住。
7.repeatable read 级别下的锁:(mysql 默认的隔离级别 -- 可重复读)
- 当使用主键、唯一索引查询时:
和RC隔离级别一样,当执行主键 a > 1 for update 条件时,会锁住全表,同样事务2 无法插入任何记录。
- 当使用普通索引查询时:
条件与上文一致,还是e = "b" 之后用事务2 查询事务1 之外的数据,发现还是可以查询到,但若此时执行插入
insert t1(b, c, d, e) values(30, 1, 1, "b"); 此时会发现这条记录是插不进去的。
但好理解的是,这样的目的本质就是为了防止 "幻读" 的发生
- 当使用全表扫描时:
同上,会将全表锁住,哪怕查询条件时 c = 1 for update,也不能更改 c = 10 的记录,因为可能会出现
你想把 c = 10 改为 c = 1 的情况,因此锁住,防止幻读现象。
注:
对于可重复读的隔离级别下, 通常会将全表、所有的行、甚至包括间隙都全部锁住。
8.乐观锁和悲观锁:
悲观锁 乐观锁
概念:查询时直接锁住记录使得其他事务不能查询 提交更新时检查版本或时间戳是否符合
语法:select * for update 使用version 或者 timestamp进行比较
实现者:数据库本身 开发者
适用场景:并发量大 并发量小
悲观锁:
悲观的认为数据处理中,肯定会有其他事务进行修改数据,因此就将数据加锁,通常依靠关系型数据库的锁机制。
不论是行锁、表锁、读写锁、都是悲观锁
乐观锁:
认为每次自己操作数据,都不会有其他事务来修改它,因此不加锁,但在更新的时候会判断此期间的数据有没有进行修改。需要
自己实现,不会发生并发抢占资源,只有在提交的时候检查,是否违反数据完整性。
原理出差CAS算法(不懂)但大概就像git一样。
场景:
读操作 远> 写操作 时,此时一个更新操作加锁就会阻塞所有的读操作,降低吞吐量,最后还要释放锁,锁还要开销,因此用乐观锁
读操作 == 写操作 都差不多时,或者系统没有响应不及时(阻塞住的情况、吞吐量瓶颈等问题)那就不要使用乐观锁,它增加了
复杂度,还带来了额外的业务风险,此时用悲观锁即可。
python中使用悲乐锁:
1.悲观锁的使用:
必须关闭mysql的自动提交属性,即执行更改操作时会立即将结果提交。set autocommit = 0
由select * from 表名 where id = 1 for update 加X锁这类型的语句衍生
ORM中:
# 开启事务装饰器 在指定函数前加上
@transaction.atomic
obj = 模型类名.objects.select_for_update.get(id = 1) # 即可实现悲观锁,若加锁失败则说明记录正在被修改,
# 需要等待或是抛出异常
2.乐观锁的使用:
乐观锁其实并不是锁。通过SQL的where子句中的条件是否满足来判断是否满足更新条件来更新数据库,通过受影响行数判断
是否更新成功,如果更新失败可以再次进行尝试,如果多次尝试失败就返回更新失败的结果。
使用乐观锁时,必须设置数据库的隔离级别是Read Committed(可以读到其他线程已提交的数据)。如果隔离级别是
Repeatable Read(可重复读,读到的数据都是开启事务时刻的数据,即使其他线程提交更新数据,该线程读取的数据
也是之前读到的数据),乐观锁如果第一次尝试失败,那么不管尝试多少次都会失败。 (Mysql数据库的默认隔离级别是
Repeatable Read,需要修改成Read Committed)。
# 首先引入
from django.db import transaction
# 以下为乐观锁视图层示例
class MyView(View):
@transaction.atomic
def post(self, request):
'''订单创建'''
count = 3 # 订购3件商品
# 设置事务保存点
s1 = transaction.savepoint()
# 乐观锁,最多尝试5次
for i in range(5):
# 查询商品的信息(库存)
try:
sku = GoodsSKU.objects.get(id=1)
except:
# 商品不存在
transaction.savepoint_rollback(s1)
return JsonResponse({'res': 1, 'errmsg': '商品不存在'})
# 判断商品的库存
if count > sku.stock:
transaction.savepoint_rollback(s1)
return JsonResponse({'res': 2, 'errmsg': '商品库存不足'})
# 更新商品的库存和销量
orgin_stock = sku.stock # 原库存 (数据库隔离级别必须是Read Committed;如果是Repeatable Read,
# 那么多次尝试读取的原库存都是一样的,读不到其他线程提交更新后的数据。)
new_stock = orgin_stock - count # 更新后的库存
new_sales = sku.sales + count # 更新后的销量
# update 商品表 set stock=new_stock, sales=new_sales where id=1 and stock = orgin_stock
# 通过where子句中的条件判断库存是否进行了修改。(并发,乐观锁)
# 返回受影响的行数
res = GoodsSKU.objects.filter(id=1, stock=orgin_stock).update(stock=new_stock, sales=new_sales)
if res == 0: # 如果修改失败
if i == 4:
# 如果尝试5次都失败
transaction.savepoint_rollback(s1)
return JsonResponse({'res': 3, 'errmsg': '下单失败'})
continue # 再次尝试
# 否则更新成功
# 跳出尝试循环
break
# 提交事务
transaction.savepoint_commit(s1)
# 返回应答
return JsonResponse({'res': 4, 'message': '创建成功'})
注:
在并发比较少时建议使用乐观锁,减少加锁、释放锁的开销。在并发比较高的时候,建议使用悲观锁。
如果乐观锁多次尝试的代价比较大,也建议使用悲观锁。
乐观锁的处理方式可以理解为在进行数据操作时不加锁,在进行数据更新时进行判断,判断更新时的数据和之前的数据是否一致,
如果不一致说明已被其他进程先进行操作
9.优化SQL的方法:
1.选取最适用的字段属性,尽可能减少定义字段宽度,尽量把字段设置NOTNULL,例如’省份’、'性别’最好适用ENUM
2.使用连接(JOIN)来代替子查询(使用多次查询来代替 JOIN)
3.适用联合(UNION)来代替手动创建的临时表
4.事务处理
5.锁定表、优化事务处理
6.适用外键,优化锁定表
7.建立索引
快照读没有完全解决幻读?
是的,MySQL没有完全解决快照读下的幻读问题。
可以做这个实验:
- 当前DB已有id 5, 10, 15三条数据。
- 事务A查询id < 10的数据,可以查出一行记录id = 5
- 事务B插入id = 6的数据
- 事务A再查询id < 10的数据,可以查出一行记录id = 5,查不出id = 6的数据(读场景,解决了幻读)
- 事务A可以更新/删除id = 6的数据,不能插入id = 6的数据(写场景,幻读不彻底)
这个很好理解,MySQL虽然通过MVCC的版本号来解决了读场景下的幻读,但对于上面第5步那种写场景的情况,其实是无能为力的,因为MVCC毕竟是无锁实现。
所以如果后续要对数据进行写操作,还是通过for update语句上锁比较稳妥,不然就可能会出现上面第5步那样的问题。